

图生视频还带声音?我把LTX 2.3塞进了自己的显卡里

上周三深夜,我在折腾一个视频生成项目。
用的是国内某平台的图生视频接口,上传了一张图,写好提示词,等了三十多秒——
“生成失败,请检查内容是否符合平台规范。”
我看了半天,也不知道哪里违规了。图就是一个普通的人物摆拍,提示词也没写什么过分的东西。重新提交,又失败。
我当时就在想:为什么我生成个视频还要看别人脸色?
就在那天,有人在群里丢了一个链接,说LTX 2.3出了GGUF量化版,能在普通显卡上跑。
我盯着那条消息看了三秒。
“图生视频+生成音频,一起的。”
又看了三秒。
然后关掉了那个一直报错的网页,开始下模型。
先说说LTX 2.3是什么来头
LTX-Video是以色列公司Lightricks搞出来的开源视频生成模型,这家公司在图像处理领域有年头了,你可能用过他们的某款修图App。
2.3这个版本比之前有几个重要升级:
- • 原生音频生成:不是后期配乐,是模型在生成视频的同时同步生成音频,口型、环境音、甚至背景音乐都是一起出来的
- • 新VAE架构:细节更锐利,头发丝、衣服纹理这些之前模糊的地方有了明显改善
- • 图生视频质量大幅提升:给它一张图,它知道这张图里的人或物”接下来应该怎么动”
- • 支持4K、50帧:虽然量化版跑不到那么高,但原始模型能力在那里
整个模型参数量是19B级别,按理说要跑起来需要巨大的VRAM。
但GGUF量化把它压下来了。
GGUF量化是什么意思?
不绕圈子,说人话。
原始模型用BF16精度存储,每个参数占2个字节。19B个参数,大概需要38GB显存——普通显卡直接劝退。
GGUF把这些参数压缩成4bit精度,体积缩小到原来的1/4到1/5。
我用的是Q4_K_S这个版本,模型文件大概10GB多一点。显卡是RTX 3080(10GB VRAM),加上文字编码器会超出,所以文字编码器走CPU,主模型走GPU——
生成一条5秒的960×544视频,大概两三分钟。有音频的那种。
说实话,第一次看到生成结果的时候,我愣了一下。
不是因为多惊艳,是因为它真的有声音。
真实上手体验
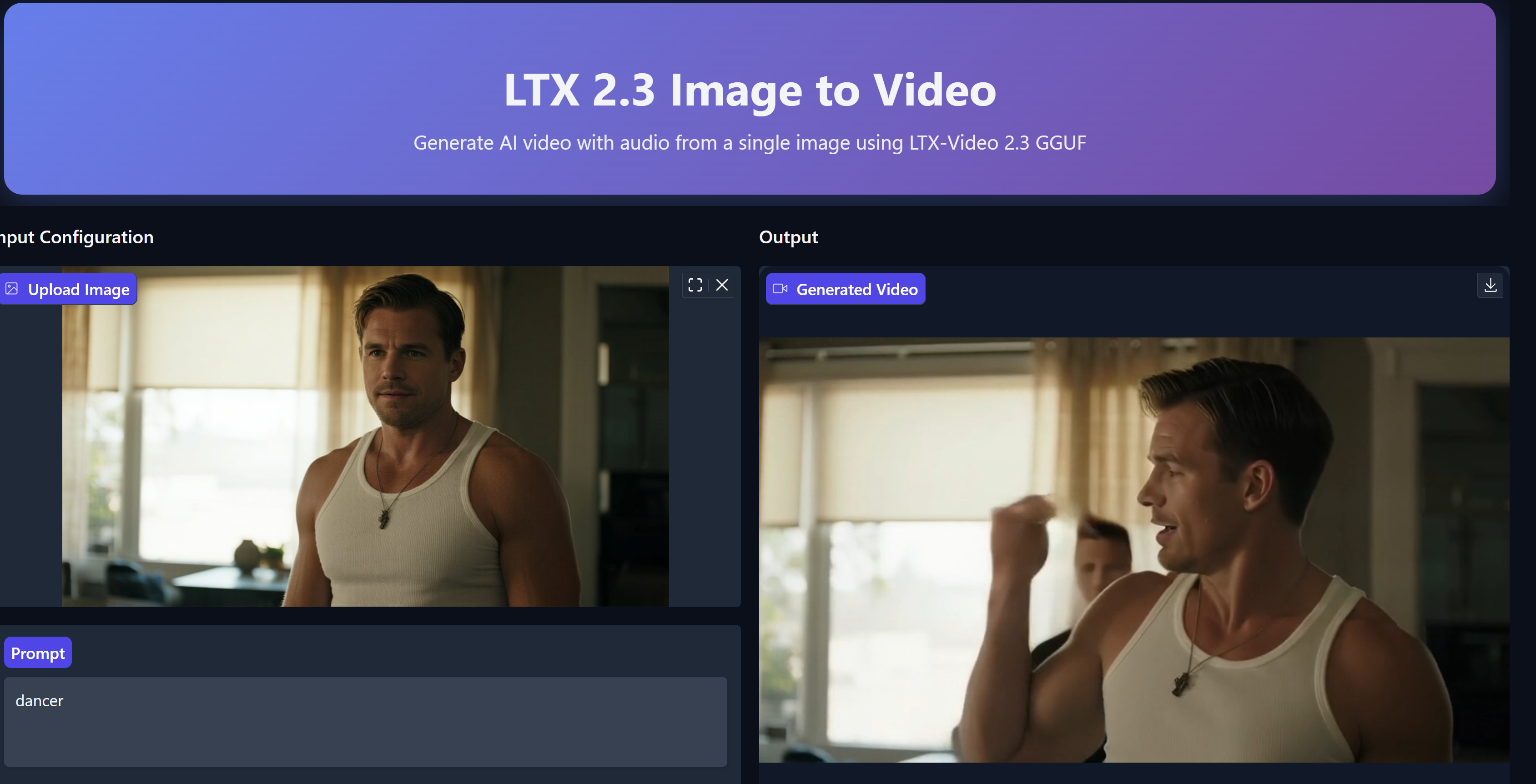
我做的是一个美女唱歌的图生视频测试。
原图是一张正脸人像。

提示词我就写了一句:美女唱歌视频。
负面提示词加了一些通用的:模糊、低质量、静止帧、水印。
然后等了大概两分半钟。
视频里的人物有了自然的嘴型动作,背景有了轻微的焦距变化,配上音频之后……你看完就明白那种感觉了。
再来一条不同输入的:
质量不是那种”哇塞完美无瑕”的级别,但是在我自己电脑上、完全离线跑出来的,这件事本身就已经让我想多想想了。
为什么选择本地跑,而不是用云端接口?
这个问题我被问过几次,每次我都觉得有点奇怪——这不应该很显然吗?
第一,隐私。
你上传到云端平台的每一张图、每一条提示词,都是别人的服务器上的数据。你不知道他们存多久,拿去做什么。
本地跑就不一样了。模型在你硬盘上,运行在你显卡里,生成的视频在你的输出文件夹。整个过程,没有任何东西离开你的电脑。
第二,没有审核。
不是说一定要做什么”违规”的事情——我说的是,你的创作自由不应该被一个不知道在哪里的算法审核员卡着。
你想让视频里的角色做什么动作,是你的事。
第三,长期来看更省钱。
云端接口按量付费,用多了费用不低。本地一次性把模型下载下来,电费而已。
如果你也想跑起来
硬件要求:
- • 最低:RTX 3080 10GB / RTX 4070 12GB,文字编码器走CPU
- • 推荐:RTX 4080/4090 16GB+,全程GPU,速度快一倍以上
- • 内存:32GB RAM(文字编码器Gemma 3 12B走CPU时需要)
- • 硬盘:至少30GB空间(模型+环境)
模型文件:
- • 主模型:
LTX-2.3-distilled-Q4_K_S.gguf(~10.7GB) - • CLIP:Gemma 3 12B fp4 + LTX文字投影层
- • VAE(视频)+ VAE(音频)各一个
我打包了一个一键启动版本,包含:
- • 完整的ComfyUI环境(已配置好所有自定义节点)
- • 预设好的工作流
- • 双击
01-run.bat直接启动,浏览器打开就能用
下载地址:https://xueshu.fun/7251

最后说一句
我折腾这些东西折腾了几年了,从最早的Stable Diffusion开始,一路到现在的视频+音频同步生成。
每次有新的能力解锁,我都会有一种类似的感觉:
科技应该是让人更自由的,不是更受限的。
一个能在你自己电脑上运行、不需要向任何人申请、不受任何内容政策约束的本地AI——这东西存在的本身,就有它的意义。
至于你打算拿它来做什么,那是你自己的事了。




